
Postdoc Application Analysis
This page explains the project. Actual results can be found here.
Contents
Context
High-energy theorists all apply to postdoctoral positions at the same time of the year. Applications are submitted before the holiday season (deadlines between November 15 and December 15). While there are on the order of 80-100 openings, these are mostly centralized in two systems: the European Joint Application and AcademicJobsOnline. Therefore, the effort required of applicants to submit a large number of applications is marginal. This results in a selection process that should be heavily dependant on measurable features based on the publication record of the applicants.
Admission decisions are usually issued between mid-December and February. An agreement between departments ensures that no position must be accepted or declined before January 7, leading to two rounds of offers usually being sent.
A fraction of applicants choose to publicize offers they have received on an unofficial “Rumor Mill“. The information on that website includes the identity of the offer recipient, the date of the rumor submission and the status of the offer. Information is available since the 2011 application year.
The Problem
What does the profile of a successful applicant look like? Prospective applicants would like to know how they compare to successful applicants.
The Data
I used raw data from three different (but linked) sources. First is the rumor mill itself: 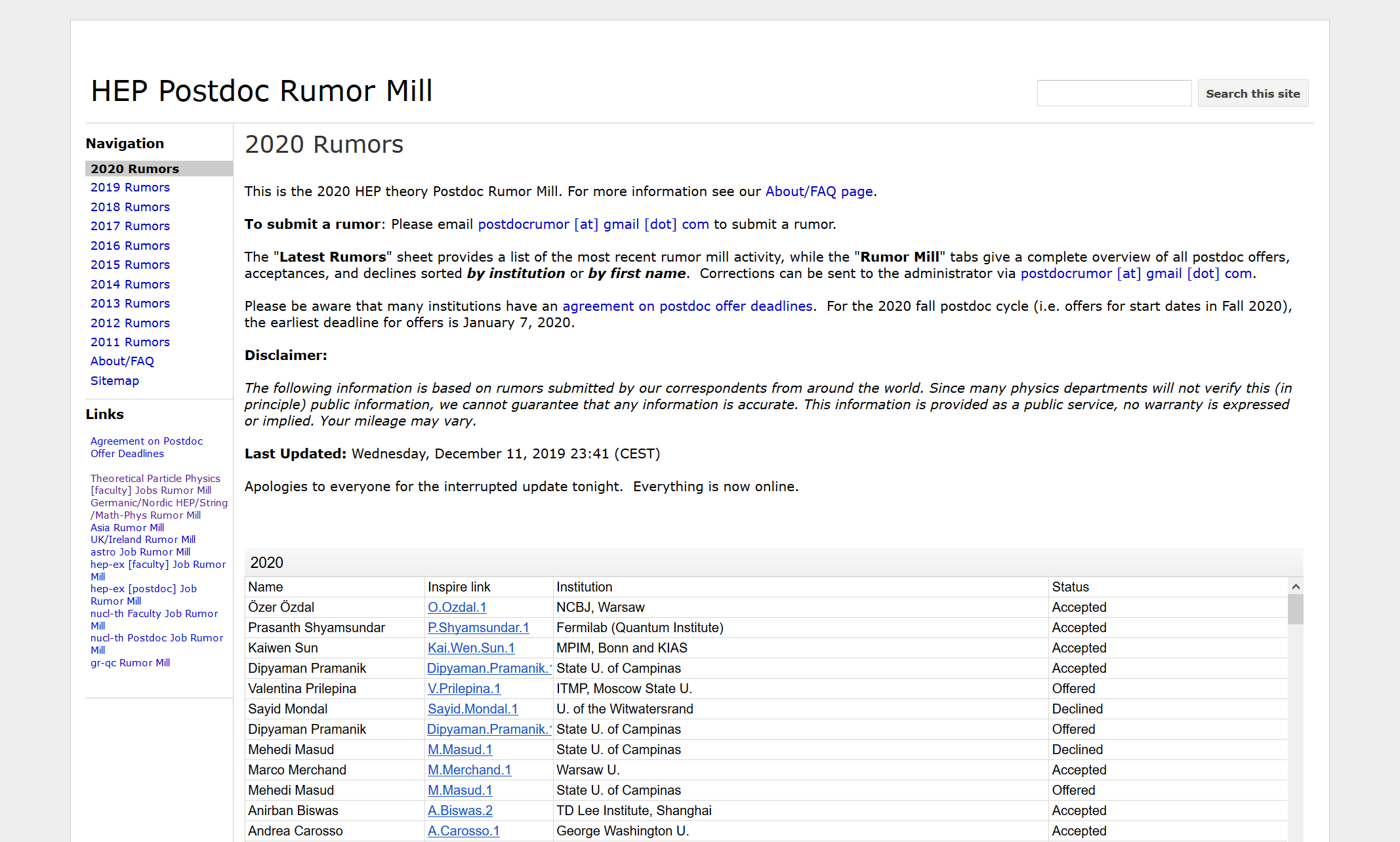
While it’s possible to use Python to download the online spreadsheets, it turns out to be easier to simply copy-paste them into Excel and do a simple search-and-replace to eliminate the HTML formatting on the URLs before exporting as a CSV file. I used data from 2017-2020. This corresponds to 969 individual applicants.
The “Inspire Link” text serves as a convenient unique identifier for applicants. It can be used to access the publication record of applicants on the InspireHEP database:
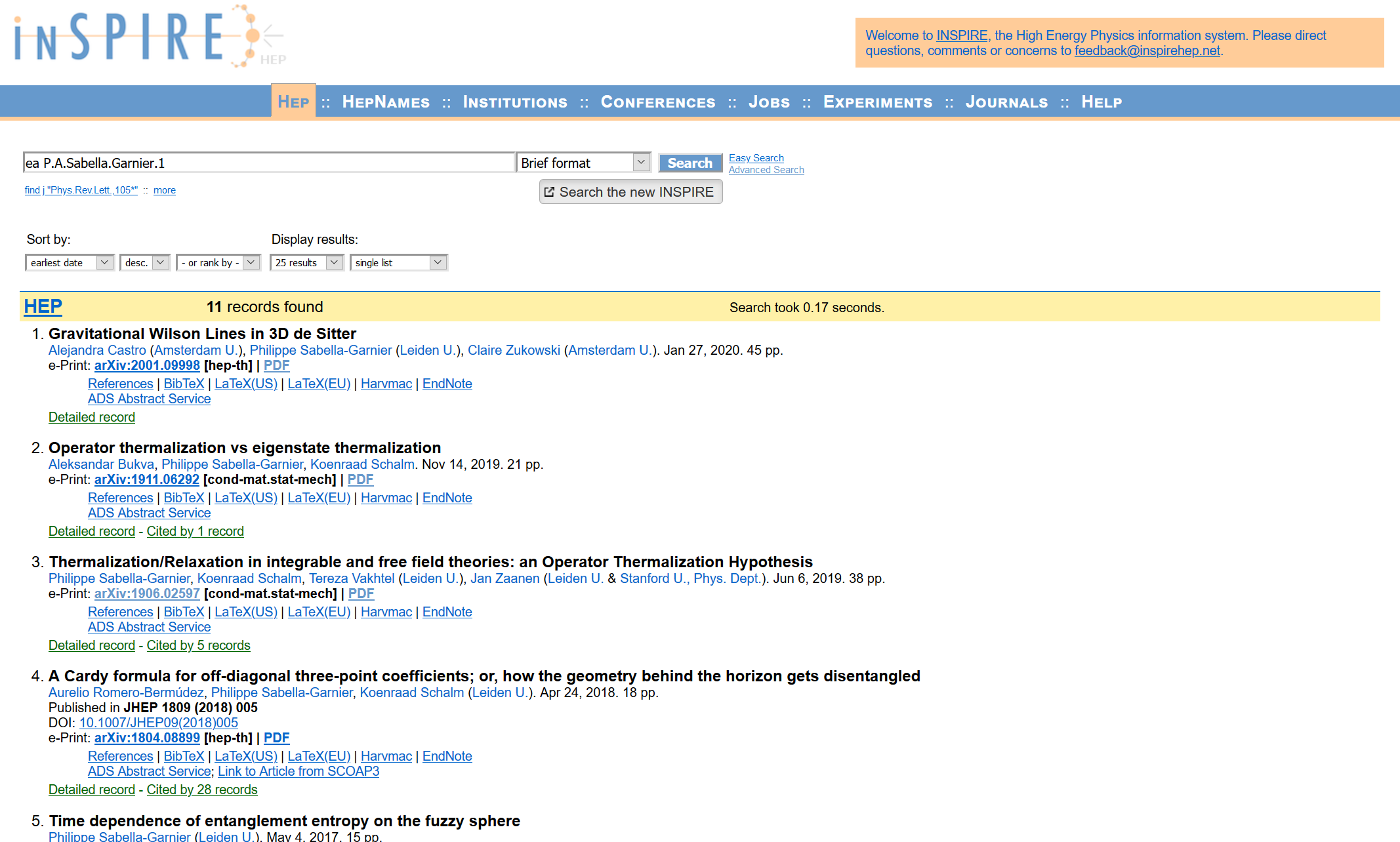
This data can be accessed through API calls from Python. The response comes in the form of JSON objects, each object corresponding to one publication. For example, the first object corresponding to the image above is:
{'creation_date': '2020-01-29T04:11:23',
'recid': 1777627,
'number_of_authors': 3,
'authors': [{'affiliation': 'Amsterdam U.',
'first_name': 'Alejandra',
'last_name': 'Castro',
'full_name': 'Castro, Alejandra'},
{'affiliation': 'Leiden U.',
'first_name': 'Philippe',
'last_name': 'Sabella-Garnier',
'full_name': 'Sabella-Garnier, Philippe'},
{'affiliation': 'Amsterdam U.',
'first_name': 'Claire',
'last_name': 'Zukowski',
'full_name': 'Zukowski, Claire'}]}
Each publication is uniquely identified by its ‘recid’. The API can return additional features, such as publication title and a list of recids of papers cited by or citing a given publication. However, we are interested in the state of things when applicants were actually applying for jobs, which can be as far back as 2017. The citation count of papers can have increased significantly since them, and of course applicants from years farther back will have more citations than more recent applicants. Since the API does not provide a feature to limit the publication year of citing records, we must come up with another solution.
One naive solution is to simply make a new call for each citing record to obtain its creation date, and only keep the ones that are old enough. However, the number of individual calls quickly grows unmanageable. Fortunately, the entirety of records can be bulk downloaded from Inspire (it contains about 650MB of data). We can thus build our own database to execute customized queries.
We create a mySQL database containing two tables: “citation” and “paper”. The citation table contains two columns: one with (multiple copies) of each recid, each of the copies corresponding to the recid of a paper that cites it.
| recid | citations |
|---|---|
| paper 1 | citing paper 1 |
| paper 1 | citing paper 2 |
| paper 2 | citing paper 3 |
| recid | title | creation_date |
|---|---|---|
| citing paper 1 | “Citing Paper 1” | 2018-01-01 |
| citing paper 2 | “Citing Paper 2” | 2020-03-01 |
With this schema, we can get a citation count for a paper with recid ID at a given DATE with
select count(*)
from citation, paper
where citation.recid = ID
and citation.citations = paper.recid
and paper.creation_date > DATE
The features
There are a number of potentially interesting features that describe the applicants which we can roughly split into two categories:
- Extensive features:
- Total number of papers
- Total number of citations
- Intensive features:
- Papers in the last year, in the last three years
- Citations per paper (median or mean)
- Maximum number of citations of a paper
Applicants’ current positions
One more important feature is not immediately accessible to us: whether the applicant is a graduate student or a postdoc. This will affect the other features, especially the extensive ones. We know from experience that postdocs and grad student are not judged according to the same criteria. Therefore, it would be very helpful to be able to create separate profiles for these two categories of applicants. Most people report their current position on their Inspire profile, but this is not accessible through the API. Furthermore, it is sometimes out of date or missing. It is usually fairly obvious from a person’s entire profile whether they are a graduate student or postdoc.
We can build a model to determine an applicant’s position at the time of application using the following features:
- Time since first paper
- Time since second paper
- Total number of affiliations
- Member of a large collaboration (y/n)
The first three features are essentially a proxy for the applicant’s ‘academic age’. The reason we cannot simply use the time since first publication or the number of affiliations is that some applicants have a publication dating back to their time as an undergrad. Whether an applicant is a member of a large collaboration or not is there to compensate for the fact that these collaborations automatically include every member on every publication, distorting the other features.
We hand-label the applicants from 2020 to create a training and test set (a matter of a few hours). Using scikit-learn, we then try different models. In all cases, we send the data through a scaler and PCA. We then compare the results of
- Support Vector Classifier (RBF and polynomial kernels),
- XGBoost,
- Random Forest,
in each case running a grid search over hyper-parameters and holding out 20% of the testing data for cross-validation. Eventually, we settle on an XGBoost model with 3 PCA components, a learning rate of 0.05, gamma=0.02, a maximum depth of 2 and L2 regularization of 0.75. This gives an accuracy of 90.6% on the testing set (which is close to evenly split).